对QQ聊天记录进行分析,由于每天产生的聊天记录比較多,所以选取的是从2月份整月的聊天记录数据。分析要产生的结果有三个,聊天记录中发消息的人前top15。统计24小时时间段那个时间段发贴人最多,还有对消息中的热词进行抽取。
对QQ用户发贴次数进行统计,须要注意QQ导出的聊天记录格式。【年月日时分秒 QQ账号相关信息】,须要对聊天记录做解析。另外对聊天内容也要做解析。
详细思路不做详解,仅仅贴结果和部分代码。相信大家一看就明确。

统计24小时时间段QQ消息数量
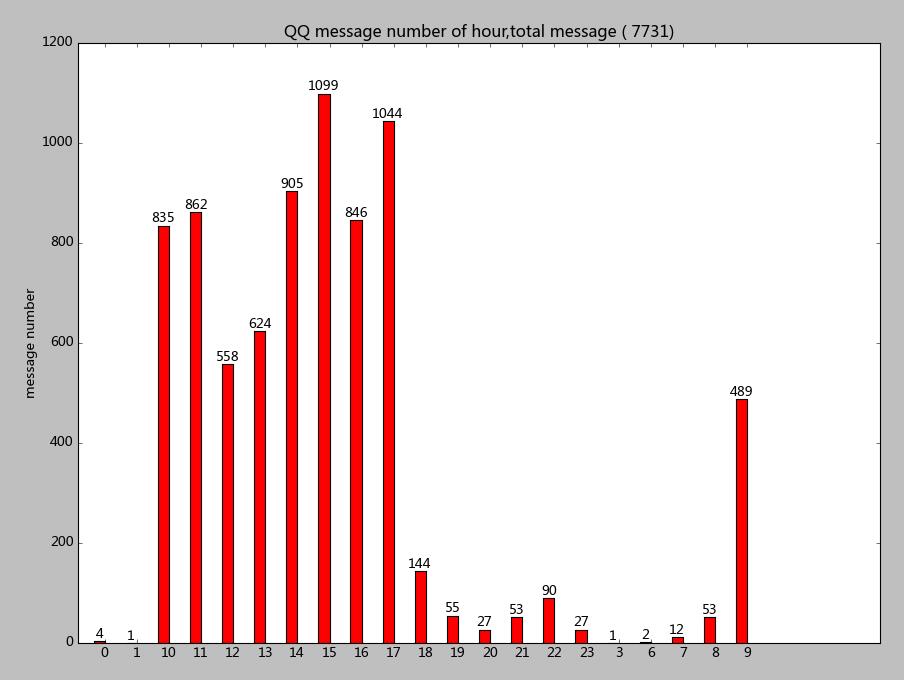
能够看出每天下午3点到5点大家都非常活跃
另一个就是对讨论的话题做分析,首先要对发的消息做分词处理。去掉一个停用词,然后按词频出现的次数统计,得到例如以下结果。

第一个表示出现的词,第二个表示在某个时间段内出现的次数,总的来说,我们这个群还算是一个技术群吧。
相关部分代码:
def userProcess(): userArray = [] contentArray = LoadUserInfo.loadUser() for userInfo in contentArray: if(len(userInfo)==3): userArray.append(userInfo[2]) print(len(userArray)) #Counter(words).most_common(10) userGroupInof = Counter(userArray).most_common(15) #print(userGroupInof) userNameLable = [] postMessageNum = [] for key,value in userGroupInof: userNameLable.append(key) postMessageNum.append(value) #performance = 3 + 10 * np.random.rand(len(people)) #error = np.random.rand(len(people)) zh_font = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') plt.barh(np.arange(len(userNameLable)), postMessageNum, align='center', alpha=0.4) plt.yticks(np.arange(len(userNameLable)), userNameLable,fontproperties=zh_font) plt.xlabel('发贴数量',fontproperties=zh_font) plt.title('java-Endless Space群(4881914)发贴最多的15个人',fontproperties=zh_font) plt.show() def hourProcess(): hourArray = [] contentArray = LoadUserInfo.loadUser() for userInfo in contentArray: if(len(userInfo)==3): messageDate = userInfo[1] hourInfo = re.split('[:]',messageDate) hourArray.append(hourInfo[0]) print(len(hourArray)) #Counter(words).most_common(10) hour_counts = Counter(hourArray) #对数据进行排序 sortByHour = sorted(hour_counts.items()) print(sortByHour) postMessageLable = [] postMessageNum = [] for key,value in sortByHour: postMessageLable.append(key) postMessageNum.append(value) print(postMessageLable) print(postMessageNum) #生成发贴柱状图 N = len(postMessageNum) ind = np.arange(N)+0.5 # the x locations for the groups #print(ind) #x轴上的数值 width = 0.35 # the width of the bars fig, ax = plt.subplots() rects = ax.bar(ind, postMessageNum, width, color='r') # add some text for labels, title and axes ticks ax.set_ylabel('message number') ax.set_title('QQ message number of hour,total message ( '+ str(len(hourArray)) + ")") ax.set_xticks(ind+width) ax.set_xticklabels(postMessageLable) def autolabel(rects): # attach some text labels for rect in rects: height = rect.get_height() ax.text(rect.get_x()+rect.get_width()/2., height, '%d'%int(height), ha='center', va='bottom') autolabel(rects) plt.show() #对导入的文件第四列做中文分词处理#对用户发出的消息进行处理def messageProcess(): wordArray = [] contentArray = LoadMessageInfo.loadMessage() print("processing original data ........") for messageInfo in contentArray: #print(messageInfo[3]) word_list = jieba.cut(messageInfo, cut_all=False) for word in word_list: #过滤掉短词,仅仅有一个长度的词 if(len(word)>1): wordArray.append(word) #print(wordArray) print("remove stop word data ........") jsonResource = open('./data/stopword.json','r',encoding='utf8') stopwords = json.load(jsonResource) #print(stopwords) for word in wordArray: print(word) if (word in stopwords): wordArray.remove(word) #print(wordArray) print("text is processing.......") word_counts = Counter(wordArray) print(word_counts) print("processing is over")